
Predictive Data Modeling: Understanding the Value and Limitations of Imputing Race and Ethnicity
The notion of fairness has been growing in prominence in the insurance industry. Awareness of fairness as a concept and a concern has increased proportionally alongside the increasing complexity of analytical models.
The definitions, concepts and objectives surrounding what is fair or what is biased when a model produces predictions on policyholders vary. Race and ethnicity are often considered dimensions of fairness and are at the forefront of protected attributes. To effectively examine data, study what a model does and what actual data shows requires that an analyst know race and ethnic information to be able to effectively and accurately evaluate data along a particular dimension.
This is not an easy or trivial task. Historically, insurance companies have taken care not to collect racial information. In some cases, insurance companies are legally prohibited from collecting racial and ethnic information. Even where such legal restrictions are not in place, an insurer may take the stance that since it has no intention of using race-based data in its work, it would prefer not to give even an appearance of relying on such data. This approach is often referred to as ensuring fairness through unawareness.
However, as utilization of data and machine learning advances, there are growing concerns that the ensuring fairness through unawareness approach is no longer enough. There are increasing calls for insurance companies to govern their analytics processes and evaluate their data and model use for indications of disparate impact to protected classes--even when the information is not directly utilized in the modeling process.
How does an insurer go about evaluating models without having ever collected racial information of policyholders? While governmental collection of census data includes such information, it is not publicly available. In aggregated form, however, census data provides some information associated with race and ethnicity. In particular, we can attain aggregated counts of population in combinations of race and Hispanic ethnicity, for example, by Zip Code Tabulation Area (ZCTA). As a separate aggregated piece of information, we can also attain aggregated counts of population in combinations of race and Hispanic ethnicity by common surnames. These are surnames with over 100 entries. In this file, remaining census information is gathered into an “Other” category for uncommon surnames.
We can blend these two separate aggregated data sets by using the Bayes formula and can infer probabilities a person is of a particular race given both the zip code and the surname. This is known as Improved Surname and Geocoding (BISG).
Furthermore, a third aggregated file is available, providing counts data associated with first names and race and ethnicity (Konstantinos Tzioumis, “Data for: Demographic aspects of first names,” Harvard Dataverse (2018), V1 https://doi.org/10.7910/DVN/TYJKEZ ). This data is based on the aggregation from three proprietary mortgage datasets. Taking the same approach as BISG and including this additional piece of information provides yet another way to impute race or ethnicity of a person based on first name, surname and zip code. This is known as Bayesian Improved First Name, Surname and Geocoding (BIFSG).
The SURGEO package in Python is an open-source option that allows someone to impute the racial and ethnic information using the BISG/BIFSG approach. Given the first name, surname, and zip code, the SURGEO package will return the probabilities the person belongs to each of six racial group categories.
I decided to give the SURGEO package a whirl and the results were interesting, to say the least.
As background, I need to share a little bit more about my family. My wife Diana and I are a mixed marriage. My wife is of European descent, with strong French and Germany ancestry. I am of Asian descent. My wife took my last name when we married. That established the three names I put through the SURGEO package.
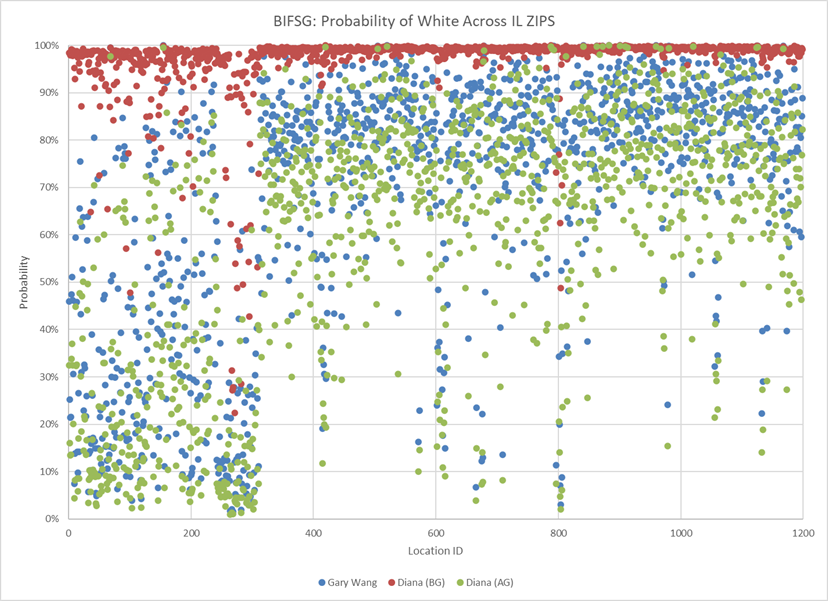
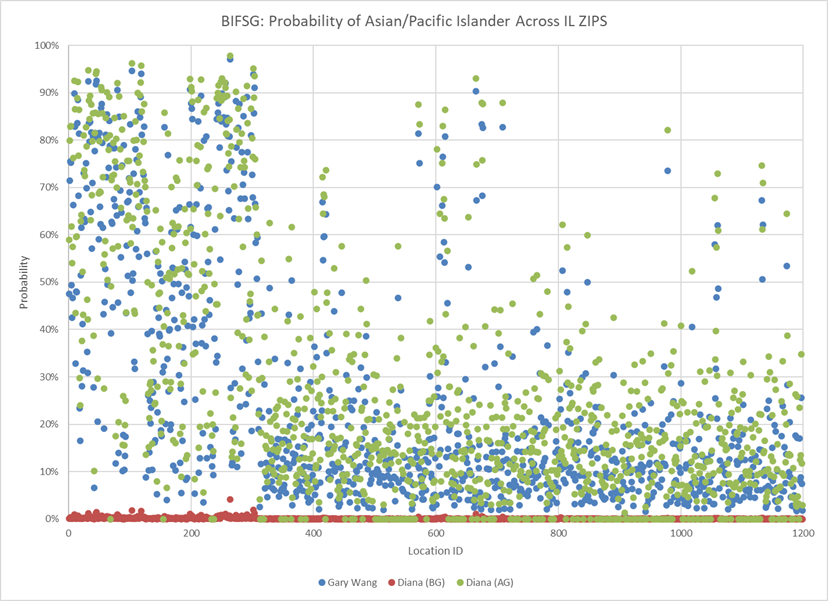
I used my wife’s maiden name, her married name, and my name as the three names used in our test of the data and SURGEO model. We took every zip code in Illinois and passed these name-zip code combinations through the SURGEO package. You can see the results in the graphics below, along with probabilities associated with some key towns in our lives:
KEY:
Blue: Gary Wang
Red: Diana (BG) - before marrying Gary
Green: Diana (AG) - after marrying Gary
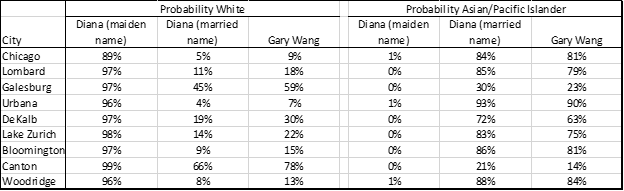
As illustrated in the above charts and graphs, Diana is clearly and properly identified as being white and not Asian-Pacific Islander (API) based on her maiden name. With her married name, the model identifies her as more Asian than me! This phenomenon highlights an important intention of the BISG/BIFSG imputation – it is meant to be utilized for study of aggregate behavior. An analyst is expected to be aware of the individual level errors of misclassification with the imputation and take those individual level errors into consideration when using the approach to label and analyze data. Yet, as an actuary (and thanks to my statistics education) and therefore able to fully appreciate the assumptions and the value and limitations of the imputation, this specific and personal example left quite an impression on me.
As an additional refinement to this experiment, I tried a fourth name. I am an immigrant and as a common practice, my parents might have kept my given Asian name, rather than giving me a new first name, Gary, before I came to the U.S. I fed my original name, Chongshiu Wang into SURGEO. Chongshiu is a very Chinese name, and I fully expected an 100% API type of answer from the package. Instead, it returned a NULL result. There may be an improvement, an opportunity for a language-based model to uncover strongly racial and ethnic names by linguistic construct.
This story and similar stories pose a challenge as we utilize information like BIFSG to analyze and assess how fair models are. While we recognize the limitations of available data, we also can appreciate the analytical value that data brings to the table.
On the other hand, detractors will always have specific examples available to them as counterexamples or demonstrations of inaccuracies and dismiss results by pointing to those instances. In my experience, specific stories are what people remember, and these stories can be very convincing particularly at a personal level.
For those engaged in the fairness discussion, I hope we are able to keep this dual nature of the BIFSG data in mind. As we utilize this invaluable census-based information to help us assess our data usage and modeling practices, we cannot let individual stories and anecdotes (despite their power) like mine dissuade us from our efforts to promote fairness.
News & Insights

What Recessions Reveal About Property and Casualty Insurance Dynamics

How the Insurance Industry is Navigating the Complex Debate Over Fairness in Pricing

Keeping It Clean: Understanding Pollution Liability Insurance and Its Future
